
How to Clean Data with pyjanitor
This article will talk about pyjanitor. It will explain how to install it, import it, and some of the key functions to help with data cleaning.
Introduction
Imagine you have started your research, and you finally finished the data collection phase. What is your next step? Data cleaning. Two words that most people who work with data dread. It can be a time-consuming process, but it is so important to the success of any research project.
Luckily, we live in a world that has wonderful programs that can help us to successfully clean data. It is fast and simple, you just have to get started! One of the most common programs used for data cleaning is R, however, did you know it can be done in Python too?
Due to Python being an open-source program, many people have developed packages that allow for data cleaning to be done using simple commands. In this post we will explore the use of one of these packages, pyjanitor. A package designed to make data cleaning as simple and as neat as possible.
pyjanitor
First let’s focus on what pyjanitor is. It was originally inspired by an R package by the name of janitor. Its many functionalities are to help make the data cleaning process neat and easy. It is used in combination with the pandas package to add more functionality and customization.
How to use it
The first thing you need to do to use the pyjanitor package is to install it. To do this you type in your terminal the command:
Pip install pyjanitor
You will also need the pandas package as pyjanitor is built off of it to install pandas you need to run pip install pandas
To be able to use pyjanitor in your work you will need to import the packages at the top of your code using the following:
Import pandas as pd
Import pyjanitor
Useful Functions Some of the useful functions in pyjanitor are:
- add_column/ add_columns
- remove_column
- remove empty
- complete
- conditional_join
- many different types of filtering systems
- move
- sort
This list is not all of the function pyjanitor offers, to see a complete list click here
Adding Columns
There are two main functions that deal with adding columns add_column and add_columns. These function can be used to add a singular column or multiple columns to a pandas’ data frame.
The first, add_column, takes in four different arguments the data frame (df), the new column name (column_name), the value you would like to be put into the row (value), and a fill true or false value that will fill in for any value that is not filled with the value argument (fill_remaining). The first three values (df, column_name, value) are required to run the function. However, the fill_remaining argument has a default of a false value. An example using this is:
>>> df = pd.DataFram({
"student_name" : ["James", "John", "Sam", "Jane"],
"student_id" : ["123", "124", "125", "126"]
})
>>> df.add_column(column_name = "grade", value= list("acba"))
student_name student_id grade
0 James 123 a
1 John 124 c
2 Sam 125 b
3 Jane 126 a
The add_columns command is slightly different from just adding a singular column. It has only three arguments the data frame (df), fill_remaining (which is the same as above), and **kargs which is a list of the columns that you would like to add with their values to be looped through and placed in the data frame. You could run this code on the same data frame shown in the previous example by running the following:
>>> df.add_columns(seat_assignment = list(range(1,5)), class_period=2)
student_name student_id seat_assignment class_period
0 James 123 1 2
1 John 124 2 2
2 Sam 125 3 2
3 Jane 126 4 2
Click here to see more documentation on adding columns.
Removal
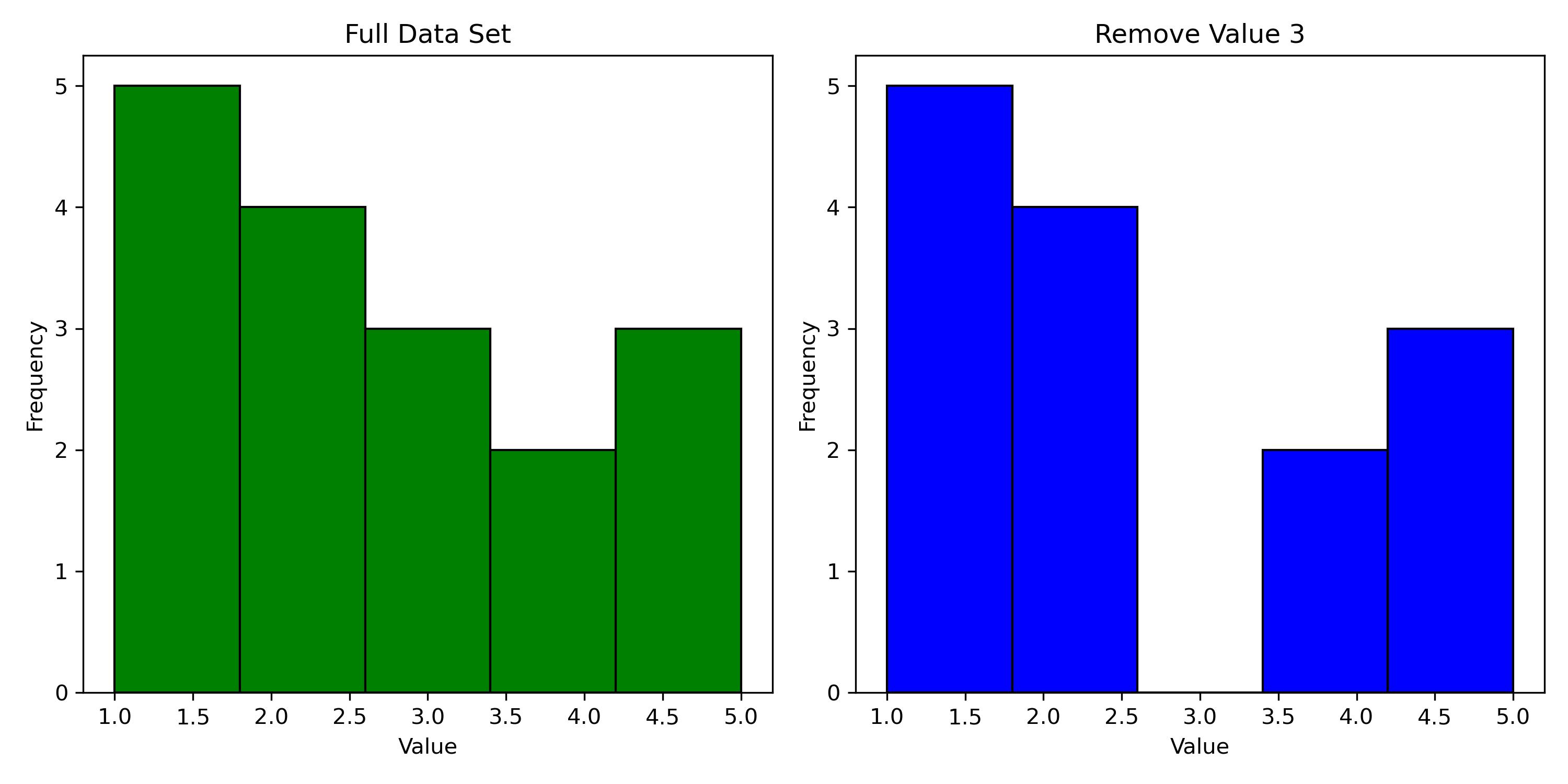
When working with data it is important to be able to remove unwanted and unnecessary data. We can either remove from the rows or remove columns in general. Some helpful features that are highlighted in the pyjanitor package are remove_column and remove_empty. Remove_column is simple and easy to use. All you need to do is input the data frame you would like to work with and the column name inside the parenthesis. Here is some code to demonstrate how to do this:
>>> df = pd.DataFram({
"1" : ["a", "f", "r", "t"],
"2" : ["q", "u", "k", "l"],
"3" : ["s", "b", "h", "e"]
})
>>> df.remove_column(column_names = ["1", "3"])
2
0 q
1 u
2 k
3 l
Remove_empty allows you to remove any missing or unwanted values, as long as they are in the same row or column. The function takes in the data frame that you would like to remove from and has a second optional argument of reset_index. Reset_index allows you to clarify if you would like the indexes for the rows or columns around the removal area to be reset or if you would like to keep them the same, the default is true, meaning the indexes will be reset to not include the removed data. An example of this is:
>>> df = pd.DataFram({
"z" : ["1", "2", "NAN", "3"],
"x" : ["NAN", "NAN", "NAN", "NAN"],
"y" : ["5", "6", "NAN", "8"]
})
>>> df
z x y
0 1 NAN 5
1 2 NAN 6
2 NAN NAN NAN
3 3 NAN 8
>>> df.remove_empty(reset_index = True)
z y
0 1 5
1 2 6
2 3 8
Click here to see more documentation on removing values.
Filtering

The final functions that we will be going over are filtering functions. pyjanitor offers a wide range of different functions that can be used to select data with certain values or within certain ranges.
The first of which is filter_column_isin. This command is special because it allows you to find certain values within a column. To use it you put the data frame you want to filter through, the column you would like to look at, and iterable (commonly lists or tuples but can be any type of pandas series). This function will go through and find each instance of that iterable in the column.
>>> df = pd.DataFram({
"student_name" : ["James", "John", "Sam", "Jane"],
"student_id" : ["123", "124", "125", "126"]
})
>>> df
student_name student_id
0 James 123
1 John 124
2 Sam 125
3 Jane 126
>>> df.filter_column_isin(column_name = "student_name", iterable = ["Sam", "Jane"])
student_name student_id
2 Sam 125
3 Jane 126
The next type of filtering is by date. Using the filter_date command pyjanitor can help you find dates with in a certain range, in a certain year, month, or day. The set up for this function is:
df.filter_date(column_name, start_date=None, end_date=None, years=None, months=None, days=None, column_date_options=None, format=None)
The none values are the default value and can be change. column_date_options allows you to are special options you can use when parsing the data. Format allows you to tell the program what format you will be using when entering the date
The filter_on command is another very helpful way to organize data. This command allows you to specify what you would the values in a column to be equal to, greater than, less than, or even not equal to. All you have to do is specify the data frame, the column, and the rule you would like it to follow when filtering the data.
>>> df = pd.DataFram({
"student_name" : ["James", "John", "Sam", "Jane"],
"test_score" : ["100", "80", "89", "95"]
})
>>> df
student_name test_score
0 James 100
1 John 80
2 Sam 89
3 Jane 95
>>> df.filter_on("test_score >= 90")
student_name test_score
0 James 100
3 Jane 95
Click here to see more documentation on flitering.
More explanation on any of the functions talked about in this article and the explanations of many other functions in pyjanitor can be found here
Conclusion
pyjanitor can be a helpful tool to make data cleaning sweet and simple. It has many useful functions that streamline the data cleaning process. In this post we covered how to add and remove columns and how to filter the data to get what we need. Now that you have learned a little bit about cleaning data using pyjanitor go try it for yourself! Next time you are tasked with cleaning data use the pyjanitor package to help get the job done!